【HBase】一些有必要知道的知识点(一)
1. Region的rowkey范围是开区间还是闭区间?
答:region的rowkey是前闭后开([start,end)),从下面这张图可以看出来:
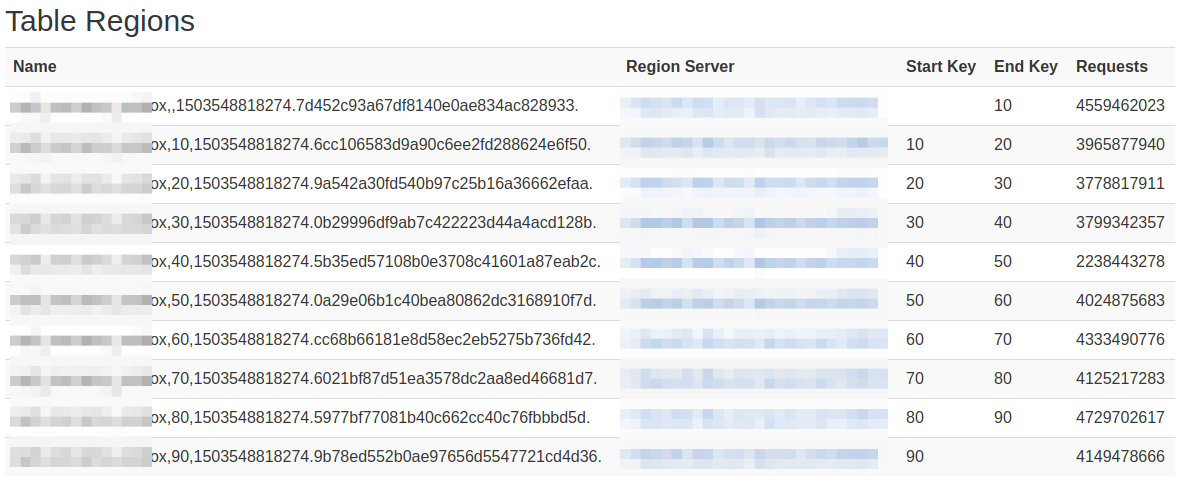
Tip:Name列都是以Start Key开始,但不是以End Key结尾,而是一串很长的数字,可以想象,应该是无限接近End Key的!
再看下面这个:预分区10个,以一位作为分区标记(hash%10),插入一条数据,且row是0开头,可以看出仅第一个region有31次请求!
建表语句:create 'xx:xxx',{SPLITS => ['1','2','3','4','5','6','7','8','9']},{NAME => 'c', COMPRESSION=>'SNAPPY', VERSIONS => 1},
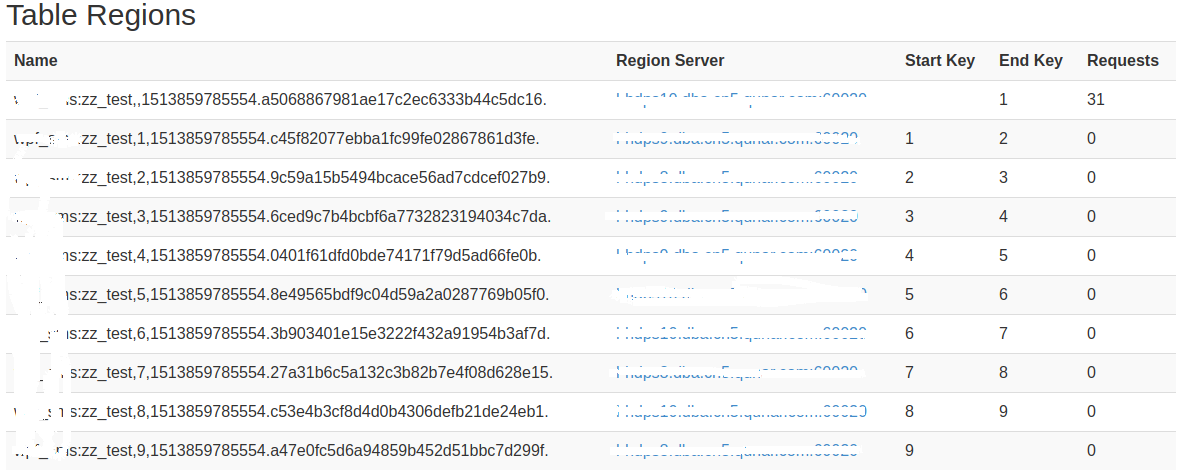
再次证明region区间是前闭后开!
2. Scan的rowkey范围是开区间还是闭区间?
答:scan是前闭后开,[startKey,endKey),如我们做分页的时候通常会拿前一页的最后一行数据的row,并在该row上面加一个byte,以跳过本行,实现快速分页查询的效果!
以上只证明了是前闭,前闭后开可以在shell中证明:scan 'xxx', {STARTROW=>'qb_car_pc2017092811451858', STOPROW=>'qb_car_pc2017092812330135'}执行结果:
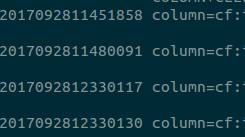
Tip:这条语句中的STARTROW和STOPROW是两个相邻的Row,从结果中可以看出查询中包含了STARTROW,但是结尾是小于STOPROW的row。
3. HTablePool线程安全么?如果线程安全,为什么?如果线程不安全,有什么影响?
答:HTablePool好像官方提供了后又删了,不过有人实现了个类似HTablePool的连接池。
谈线程安全,我想应该是谈HTable,Htable是一个非线程安全的方法,每次操作都需要重新new一个HTable实例,频繁的创建性能开销也不大,
其底层是使用一个线程池来与Hbase service做交互!
但是高qps下,还是可以做一个HTable的对象池,(。。。)我这里基于0.98.6-hadoop2版的client实现了一个HTable的线程池!
如果多线程下使用同一个HTable实例,最直观的结果是数据不完整或丢失(- -我这里踩过一个大坑),这个好像跟Htable在本地的cache相关!
4. 根据row的查询方法:Regex,Substring,Prefix,Rang查询效率怎样?
答:结论:Rang >= Prefix > Substring >=Regex,上述结论基于约12亿数据,8个RS,预分区10个,每个100G,版本HBase client 0.96下统计;
row格式如下:xx + 20171108 + mobile + onlyBunch,相同条件下scan的范围查询和前缀查询效率相当,正则和sustring的方式查询非常慢,基本不可用。
所以,数据了较大的情况下,row的设计最多能包含两个条件(一般是xxId+时间),更多条件推荐新建一张保存原表rowKey的HBase索引表。
也即,类似UserId + Mobile + 时间戳的rowkey设计是不可取的!
另外,查询效率差别原因:rang和prefix可以通过前缀确定一个比较小的范围,而substring 和regex则是全表扫描row,在加上字符串匹配,所以效率会非常低!
5. Filter的实现原理
答:所有的Filter都是基于Filter和FilterBase的,自定义一个Filter,需要将其编译成jar包,然后放到集群上然后重启集群。
其中最重要的两个需要实现的方法就是:boolean filterRowKey(byte[] buffer, int offset, int length)
和ReturnCode filterKeyValue(Cell ignored),前者决定是否过滤掉这个rowkey,后者决定列的问题:INCLUDE,INCLUDE_AND_NEXT_COL,SKIP,...等等。
Filter是在RegionServer上中读取数据时使用,将过滤操作放到RS上可以减少网络开销,每次scan,其携带的每个Filter都会在每个RegionServer上实例化一个,并按照Filter加入List的顺序执行。
Tip:详情可参考《HBase实战》中的4.8节,关于过滤数据的阐述。
6. scan中的setCaching(int),setBatch(int),setMaxResultSize(long),setCacheBlocks(boolean)方法的含义?
setCaching(int)设置每次rpc请求缓存在client的行数(rows),ResultScanner每次next()调用从client的Caching中拿数据。默认是-1即不设置,此时会使用HTable.setScannerCaching(int)中的设置值(默认每次rpc返回100条结果);
设置cache大可以优化性能,但是太大了会花费很长的时间进行一次传输,且需要更多的client内存。
每次rpc返回的结果还受setMaxResultSize(long)参数影响,setMaxResultSize(long)表示每次rpc返回的最大数据量。
setBatch(int)用于限制每次ResultScanner的next()调用返回的column size(个人理解为限制返回一行row中列的数量)有些row特别大,所以需要分开传给client,就是一次传一个row的几个column。默认-1即不限制。
batch和caching,MaxResultSize和hbase table column size共同决定了rpc的次数。
setCacheBlocks(boolean):指定本次scan请求是否禁止server端的block caching
To explicitly disable server-side block caching for this scan
其他参数:getWriteBufferSize:2097152isAutoFlush:truemaxKeyValueSize=10485760
https://docs.transwarp.io/4.7/goto?file=HyperbaseManual_hbase-architecture-chapter.html#hbase-architecture-chapter
http://blog.csdn.net/lin_wj1995/article/details/72967494
7. ResultScanner的机制
答:首先与HBase相关的默认参数都在org.apache.hadoop.hbase.HConstants中定义,
表相关的参数在org.apache.hadoop.hbase.client.TableConfiguration中设置,TableConfiguration中有两个参数:scannerCaching和scannerMaxResultSize
默认是:scannerCaching=100,scannerMaxResultSize=2097152L。
看ResultScanner的实现:org.apache.hadoop.hbase.client.ClientScanner#next1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public Result next() throws IOException {
// If the scanner is closed and there's nothing left in the cache, next is a no-op.
if (cache.size() == 0 && this.closed) {
return null;
}
if (cache.size() == 0) {
// Contact the servers to load more Results in the cache.
loadCache();
}
if (cache.size() > 0) {
//取出数据
return cache.poll();
}
// if we exhausted this scanner before calling close, write out the scan metrics
writeScanMetrics();
return null;
}
这里,应该是很明了了,ResultScanner并不是一次把所有符合查询条件的数据都加载到client,而是每次取一部分。
8. 如何找到region的
答:HBase中有两个特殊的表-ROOT-表和.META.表,-ROOT-表永远只有一个region,.META.表可以切分成多个region。他们都保存在RegionServer上。-ROOT-表保存了.META.表的位置,.META.表保存了每个region所在的位置。
设-ROOT-表内容如下:1
2M:1001 - M:1009 M1 RS1
M:1010 - M:1019 M1 RS2
-ROOT-告诉client,scan的rowkey范围1001~1009的region可以在RS1的.META.表中找到,同理10010~1019.
设RS1的.META.表内容如下:1
2T:1001 - T:1005 R1 RS1
T:1006 - T:1009 R2 RS2
.META.表告诉client,rowkey范围在1001~1005之间的可以在RS1的R1 region中查找到。
注:-ROOT- 和 .META.的region也不例外,保存的row范围是前闭后开!上面例子只是一个表述。
总结,查找过程:client ==> -ROOT- ==> .META. ==> region,首次查询client会去Zookeeper中拿到-ROOT-表信息,随后client会缓存-ROOT-表和.META.表信息。
