【HBase】一次rowkey设计
前言:一次HBase的rowkey设计,走了些弯路,踩了些坑,故这里记录下来,供参考引以为戒吧。在介绍rowkey设计之前,有必要对HBase有个最基本的了解。
三. 设计Rowkey演化
1,rowkey设计原则
- 全局唯一,hbase以此为索引检索数据,一个rowkey对应一行数据!
- 以字典顺序排序,最大64k,存为byte[]字节数组,尽可能短(若rowkey=100byte,1000w行,就要占近1G空间)!一般设计在
10-100byte之间,一个ASCII字符,占1byte!
字典顺序,也可以理解成ASCII表的顺序,比如:数字+字母组合,范围可以是0-z - 将经常读或最近可能被访问的数据放到一起!而且要保证数据均匀分布到不同的Region中。
且要防止热点问题,如果热点数据都放在一个Region中,多个client访问同一个Region,造成单台服务器压力太大,出现热点问题,性能不佳! - rowkey的高位设计成离散的。
如果将时间戳放在rowkey的高位,会导致所有数据都集中在一个Region,造成热点问题。如:201707218613512345678abcd,这种rowkey就会出现热点问题!每天所有数据都会写入同一个region - 一个rowkey对应二维表中的一行(可以看做唯一键)
Tip:所说的高位表示一串字符串,从左到右等价于从高位到低位。
2,rowkey设计策略
Salt,即在rowkey高位加几位随机数,随机数的种类和你预期使用的Region数量保持一致。Hash,为使高为离散,使用Hash值放在高位。reverse,即反转字符串序列,通常高位是不变的(如2017),反转后经常改变的部分放在前面了,rowkey离散了,但是rowkey会变得无序!
常见反转例子:
(1) 手机号反转:相比手机号的固定开头,发转后会使得数据更加离散。
(2) 时间戳反转:可以设计成key+ (Long.Max_Value - timestamp)的格式rowkey,这样最近的数据值最小,scan (key) 获取的是最新是数据,保证了升序。
且范围查询比较方便,如startRow:(Long.Max_Value - 起始时间),stopRow:(Long.Max_Value - 结束时间)
3,从一个场景开始
场景:HBase保存所有的message记录,每条message包括手机号,账号,时间,内容,… …等等,消息写入量大,查询场景有:手机号+时间,账号+时间,手机号+账号+时间,其中一个一个账号可能对应多个手机号。
假设message数量在十的10次方以上级别,写入qps在1w左右,设计一个rowkey,既能满足基本的查询要求,还能保证正常读写。
根据上面的背景介绍,承担较高qps的写入,需要rowkey离散,多region分担写压力;rowkey的设计必须至少包含手机号,账号,时间;
下面谈谈可能的rowkey设计思路:
rowkey = [dateTime] + [mobile] + [reverse timestamp],如:2017071386136123498761503382954
优点:优点在于数据按天存储,数据可以按天,按月进行统计。
缺点:热点问题,如果读写qps太高很可能会出现问题。跨天查询需要多次查询。rowkey = [mobile reverse] + [reverse timestamp]
如果,这样设计,建表时采用预分区,既不会出现热点问题,也能满足手机号+时间查询。但是账号+时间查询还没有解决rowkey = [mobile reverse] + [MD5 account] + [mobile] +[reverse timestamp]
看似合理,其实完全不可行,当数据量到达一定量级后,rowkey的正则和substring搜索完全不可用!
有个问题:如果我将每个Region设置为10G,这样开始可能数据在一个Region中,但是随着数据量变大,10GRegion填满,发生Split,那么一个Region就均分成两个小范围的StartRowkey和StopRowkey了,这样读写压力不就分到多个RegionServer中了吗?
答:看似很有道理,首先split大概从是中间一分为二,另外多数业务场景想Rowkey是递增的,即数据通常是有序存入storeFile中的,也就是说写最终还是只会在一个Region上写,并不能解决热点问题!
好吧,上面都是瞎DIY,下面提出一种能够满足三个条件组合查询,并能实时统计功能的rowkey设计:
数据表rowkey设计:reverse mobile(定长)+ reverse timestamp(19) + 唯一串(可不要)
索引表rowkey设计:z + 20171212 + md5 account(定长16) + mobile(定长处理) + reverse time (仅时间反转定长9) + 唯一串(可不要)
建表时采用预分区:
数据表,手机号前两位作为预分区(20个):1
SPLITS => ['05','10','15','20','25','30','35','40','45','50','55','60','65','70','75','80','85','90','95']
索引表将x作为预分区(x是 hash account % 10 == 10个):SPLITS => ['1','2','3','4','5','6','7','8','9']
另一个可以参考的方案:预分区+Hash散列
方案叙述:rowkey = [hash mobile] + [date time] + [mobile] +[reverse timestamp]
- 预分区:表示在创建表的时候指定Region个数或范围。
指定Region个数的语法:create 'namespace:table_name', {NUMREGIONS => 5, SPLITALGO => 'HexStringSplit'}, {NAME => 'cf', COMPRESSION=>'SNAPPY', VERSIONS => 1}
建表时会创建5个分区,但是分区的rowkey范围会根据rowkey动态决定。
指定Region个数和Region范围:1
create 'namespace:table_name',{SPLITS => ['10', '20', '30', '40', '50', '60', '70','80','90']},{NAME => 'cf', COMPRESSION=>'SNAPPY', VERSIONS => 1}
创建表时指定创建10个分区,范围从0~10,10~20,…,90~十个预分区,此时就需要Hash散列,在rowkey前两位随机产生0~100的随机数。
- Hash散列:表示根据rowkey中某个字段Hash出一个范围数字,作为rowkey的高位,这样这个散列可以重现,使得我们能通过rowkey进行get查询,也可以进行范围查询。
Hash出来的数字是可以根据rowkey中某个字段重新计算出来的,如果要随机产生0~100的随机数最简单与100取余即可,但实际应用中可能需要进行数据抽样分析,确保能均匀分散到每一块。如,Hash Mobile可以直接取mobile后两位作为rowkey的高位,也可以先获求一个mobile的Hash值,再与100取余。
另外,如果服务器RegionServer只有5个,那么预分区设置成5个或许会更好。
这里给出,测试约1500w数据的写入结果: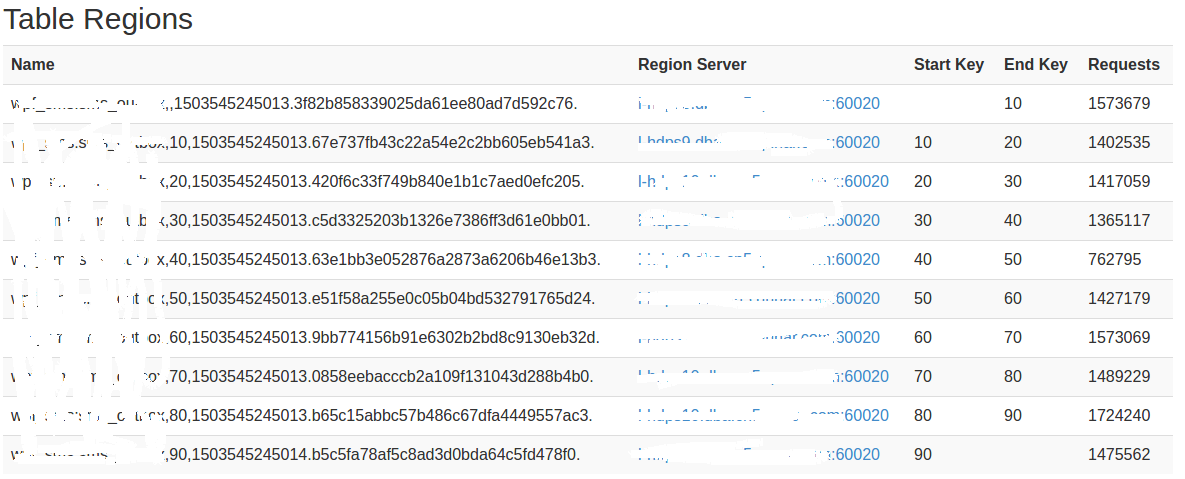
数据能够均匀分布在不同的RS上。其中,前两位是取mobile的最后一位和一个随机数(这里选择的是区间中间值5)包括(05,15,25,35,45,55,65,75,85,95)等10种情况。当然,这里取一位也可以,但是这里考虑到其他情况所以选择两位,可能还有其他很好方法具体情况就具体分析了。
有个问题:如果具体业务中历史数据随着时间的推移使用和查询几率越来越小,会不会因为历史数据和最新数据混合在一起导致查询效率的降低?
答:不会!首先rowkey的设计一般会根据时间递增或递减,所以在Region中数据会按照时间排列在一起,最新的数据始终会在最前或最后,rowkey的范围查询,并不会遍历到历史数据!并且HBase还有BloomFilter和Cache等策略保证查询不那么低效。
最后,在实际的情景中,可能由于各种问题,得有些折中。这里不是为了做抛砖引玉的作用,仅作引以为界罢了。
